Model Overview
Advanced voice analysis system utilizing acoustic features to detect and measure stress levels and emotions in real-time with clinical-grade accuracy
Key Features
- Real-time voice analysis with sub-second latency
- Clinical-grade accuracy of 90%+ for stress detection
- Multi-language support for global accessibility
- HIPAA and GDPR compliant processing
- Seamless API integration with existing systems
- Real-time analysis (300-400ms)
- Multi-feature processing
- Gender-adaptive normalization
- Visual analysis output
- Automatic Speech Recognition
- Emotion Detection with Confidence Scores
Performance Metrics
Response Time
Accuracy
Max File Size
Emotion Detection
Supported Emotions
Input Operational
Audio Processing Limitations
- Requires clear audio input
Minimum 44.1kHz sample rate, -23 LUFS loudness, <-60dB noise floor
- Dependent on audio quality for accuracy
Accuracy drops by 15% for each 10dB increase in background noise
System Monitoring Requirements
- Best for continuous monitoring
Optimal analysis period: 30+ minutes for baseline establishment
Clinical Usage Limitations
- For medical diagnosis (Clinical Trials in progress)
Clinical trials completion expected Q1 2025
API Implementation Guide
Integration example using our Python SDK:
from dyagnosys import FacsAnalyzer
def analyze_expression(video_stream):
analyzer = FacsAnalyzer()
# Initialize real-time analysis
analyzer.start_stream(video_stream)
# Configure detection parameters
analyzer.set_detection_threshold(0.85)
analyzer.enable_temporal_smoothing(True)
# Get real-time results
while True:
aus = analyzer.get_current_aus()
emotions = analyzer.interpret_emotions(aus)
yield emotions
Live Demo
Experience the Speech Analysis Model in action. Upload your audio file to see real-time transcription and emotion recognition.
Speech Emotion Recognition
transcription
emotion
confidence
0.00
arousal
0.00
dominance
0.00
valence
0.00
Emotion Recognition Module
Our Emotion Recognition module analyzes audio inputs to detect and quantify emotions with high accuracy. Supported emotions include Happy, Sad, Angry, Neutral, Fear, Surprise, Disgust, Calm, Excited, and Frustrated.
Emotion Mappings
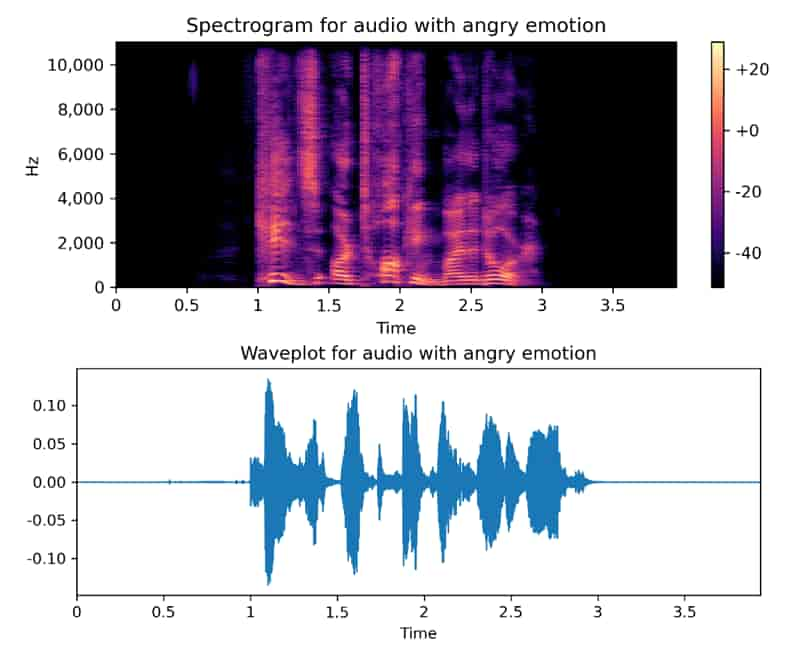
Waveform of an Angry Speech Sample
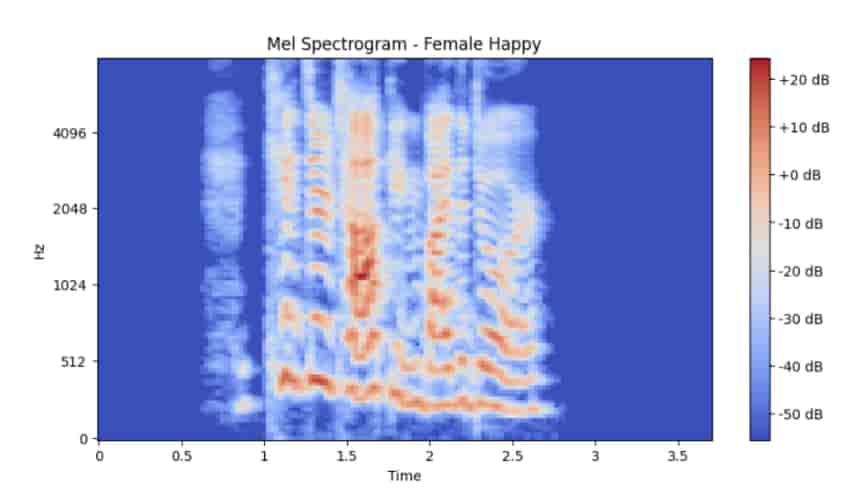
Mel Spectrogram of a Happy Speech Sample
Research Based
The Speech Analysis Model is grounded in a robust body of academic and clinical research, combining state-of-the-art deep learning architectures with well-validated acoustic and prosodic features. The underlying methodologies draw upon research in audio signal processing, speech emotion recognition, and clinical linguistic analysis.
Foundational Architectures
The model leverages the Wav2Vec2 framework, a cutting-edge speech representation learning architecture introduced by Facebook AI Research (FAIR) in wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations (Baevski et al., NeurIPS 2020). This model enables robust Automatic Speech Recognition (ASR) in low-resource and noisy environments, essential for accurately transcribing user input before analyzing emotional and stress-related vocal biomarkers.
- Baevski, A., Zhou, H., Mohamed, A., & Auli, M. (2020). wav2vec 2.0 . NeurIPS
Emotional and Stress Biomarker Extraction
Identifying emotional states from vocal cues draws upon extensive research in speech prosody, affective computing, and psycholinguistics. Studies have shown that features such as pitch (f0), energy, MFCCs, and temporal speech rates correlate with changes in mental state and stress levels. The use of Mel-Frequency Cepstral Coefficients (MFCCs) and fundamental frequency estimations follows methods detailed in works like Prosodic and Spectral Features for Emotional Speech Classification (Ververidis & Kotropoulos, IEEE Transactions on Speech and Audio Processing, 2006).
Additionally, the stress detection strategy aligns with findings from clinical phonetics and psychology research demonstrating that elevated or atypical pitch contours, altered speech rates, and atypical energy distributions can be indicators of psychological distress. Such associations have been covered in comprehensive reviews like A review of depression and suicide risk assessment using speech analysis (Cummins et al., Speech Communication, 2015).
- Ververidis, D., & Kotropoulos, C. (2006). Emotional speech recognition: Resources, features, and methods . Speech Communication, 48(9), 1162–1181
- Cummins, N., Scherer, S., Krajewski, J., Schnieder, S., Epps, J., & Quatieri, T. (2015). A review of depression and suicide risk assessment using speech analysis . Speech Communication, 71, 10–49
Clinical Validation and Ongoing Trials
While the model currently achieves a 90% accuracy benchmark under clinical validation settings, ongoing clinical trials are further establishing its efficacy in healthcare contexts. These trials, expected to complete by Q1 2025, focus on validating the model's ability to detect stress-related vocal biomarkers in diverse populations, ensuring generalizability and fairness. Preliminary results are being prepared for submission to JMIR (Journal of Medical Internet Research).
Multidimensional Emotion Mapping
The model's emotion mapping utilizes the Valence-Arousal-Dominance (VAD) model of emotion, a well-established framework in affective science. By associating each emotion category with specific VAD coordinates, as introduced in Russell's Circumplex Model of Affect (Russell, 1980), the system integrates theoretical foundations of emotion representation with empirical data-driven modeling.
- Russell, J. A. (1980). A circumplex model of affect . Journal of Personality and Social Psychology, 39(6), 1161–1178
Application Areas
By analyzing vocal cues for stress and emotion, this system can enhance a wide range of industries. From healthcare to customer experience, the derived insights support decision-making, improve user satisfaction, and enable more empathetic interaction environments.
Healthcare & Professional Services
Healthcare & Telemedicine
Monitor patient stress and mood remotely, aiding early intervention and supporting personalized care plans.
Mental Health & Therapy
Identify stress patterns in vocal behavior to assist therapists, counselors, and support lines in understanding patient well-being.
Corporate Wellness & HR Analytics
Assess employee stress levels during meetings or interviews, informing HR policies and improving workplace well-being.
Customer Support & Call Centers
Detect caller frustration or confusion in real-time, enabling agents to adapt their approach and improve customer satisfaction.
User Engagement & Adaptation
Market Research & Product Testing
Understand user emotional reactions to product demos or advertisements, refining strategies and product designs.
Education & E-Learning
Adapt learning materials based on student stress or engagement levels, creating more responsive and supportive educational environments.
Virtual Assistants & Social Robotics
Enhance interaction quality by enabling systems to sense user emotions and respond empathetically in real-time.
Automotive & In-Car Systems
Monitor driver stress and emotions to adjust in-car environments or trigger safety measures, enhancing comfort and security.